
Mapping the Conceptual Territory in AI Existential Safety and Alignment
Published:
Throughout my studies in alignment and AI-related existential risks, I’ve found it helpful to build a mental map of the field and how its various questions and considerations interrelate, so that when I read a new paper, a post on the Alignment Forum, or similar material, I have some idea of how it might contribute to the overall goal of making our deployment of AI technology go as well as possible for humanity. I’m writing this post to communicate what I’ve learned through this process, in order to help others trying to build their own mental maps and provide them with links to relevant resources for further, more detailed information. This post was largely inspired by (and would not be possible without) two talks by Paul Christiano and Rohin Shah, respectively, that give very similar overviews of the field,1 as well as a few posts on the Alignment Forum that will be discussed below. This post is not intended to replace these talks but is instead an attempt to coherently integrate their ideas with ideas from other sources attempting to clarify various aspects of the field. You should nonetheless watch these presentations and read some of the resources provided below if you’re trying to build your mental map as completely as possible.
(Primer: If you’re not already convinced of the possibility that advanced AI could represent an existential threat to humanity, it may be hard to understand the motivation for much of the following discussion. In this case, a good starting point might be Richard Ngo’s sequence AGI Safety from First Principles on the Alignment Forum, which makes the case for taking these issues seriously without taking any previous claims for granted. Others in the field might make the case differently or be motivated by different considerations,2 but this still provides a good starting point for newcomers.)
Clarifying the objective
First, I feel it is important to note that both the scope of the discussion and the relative importance of different research areas change somewhat depending on whether our high-level objective is “reduce or eliminate AI-related existential risks” or “ensure the best possible outcome for humanity as it deploys AI technology.” Of course, most people thinking about AI-related existential risks are probably doing so because they care about ensuring a good long-term future for humanity, but the point remains that avoiding extinction is a necessary but not sufficient condition for humanity being able to flourish in the long term.
Paul Christiano’s roadmap, as well as the one I have adapted from Paul’s for this post in an attempt to include some ideas from other sources, have “make AI go well” as the top-level goal, and of course, technical research on ensuring existential safety will be necessary in order to achieve this goal. However, some other research areas under this heading, such as “make AI competent,” arguably contribute more to existential risk than to existential safety, despite remaining necessary for ensuring the most beneficial overall outcomes. (To see this, consider that AI systems below a certain level of competence, such as current machine learning systems, pose no existential threat at all, and that with increasing competence comes increasing risk in the case of that competence being applied in undesirable ways.) I want to credit Andrew Critch and David Krueger’s paper AI Research Considerations for Human Existential Safety (ARCHES) for hammering this point home for me (see also the blog post I wrote about ARCHES).
The map
The rest of this post will discuss various aspects of this diagram and its contents:
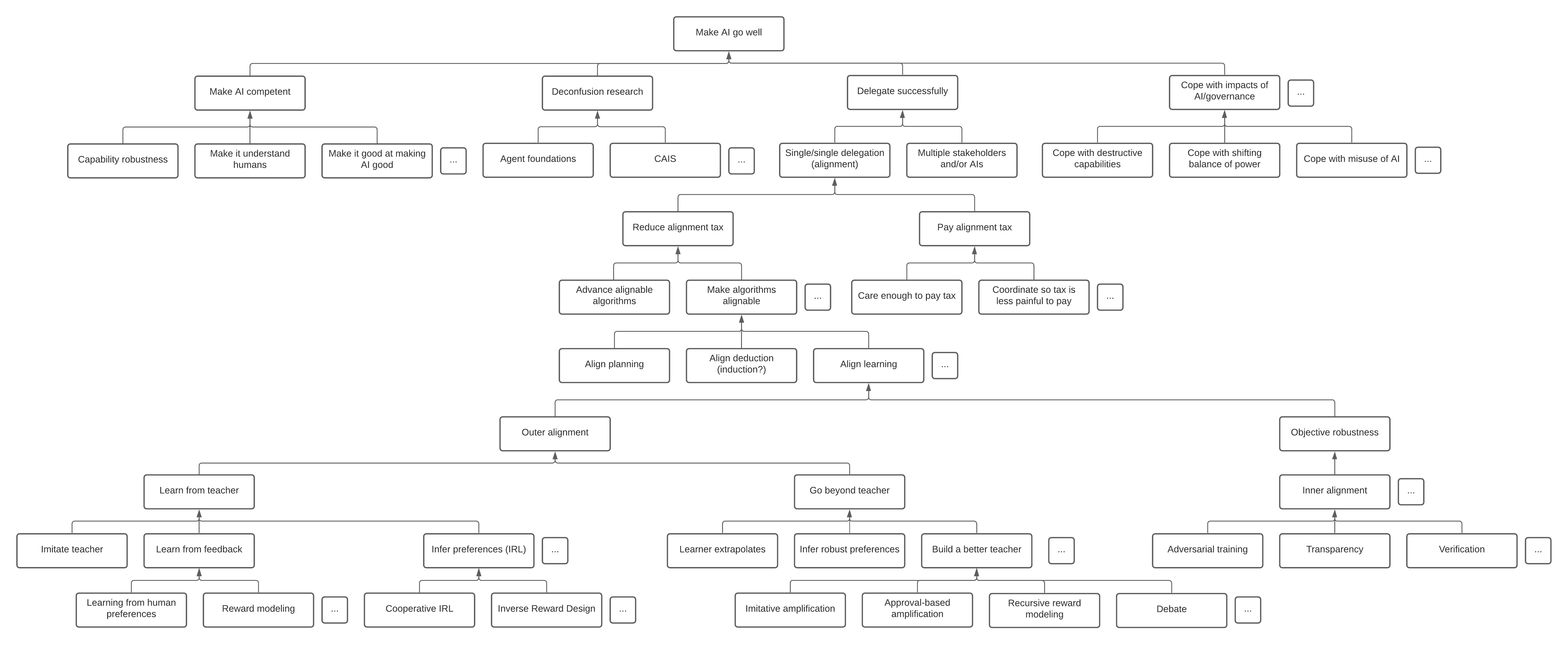
I have to strongly stress that this is only marginally different from Paul’s original breakdown (the highlighted boxes are where he spends most of his time):
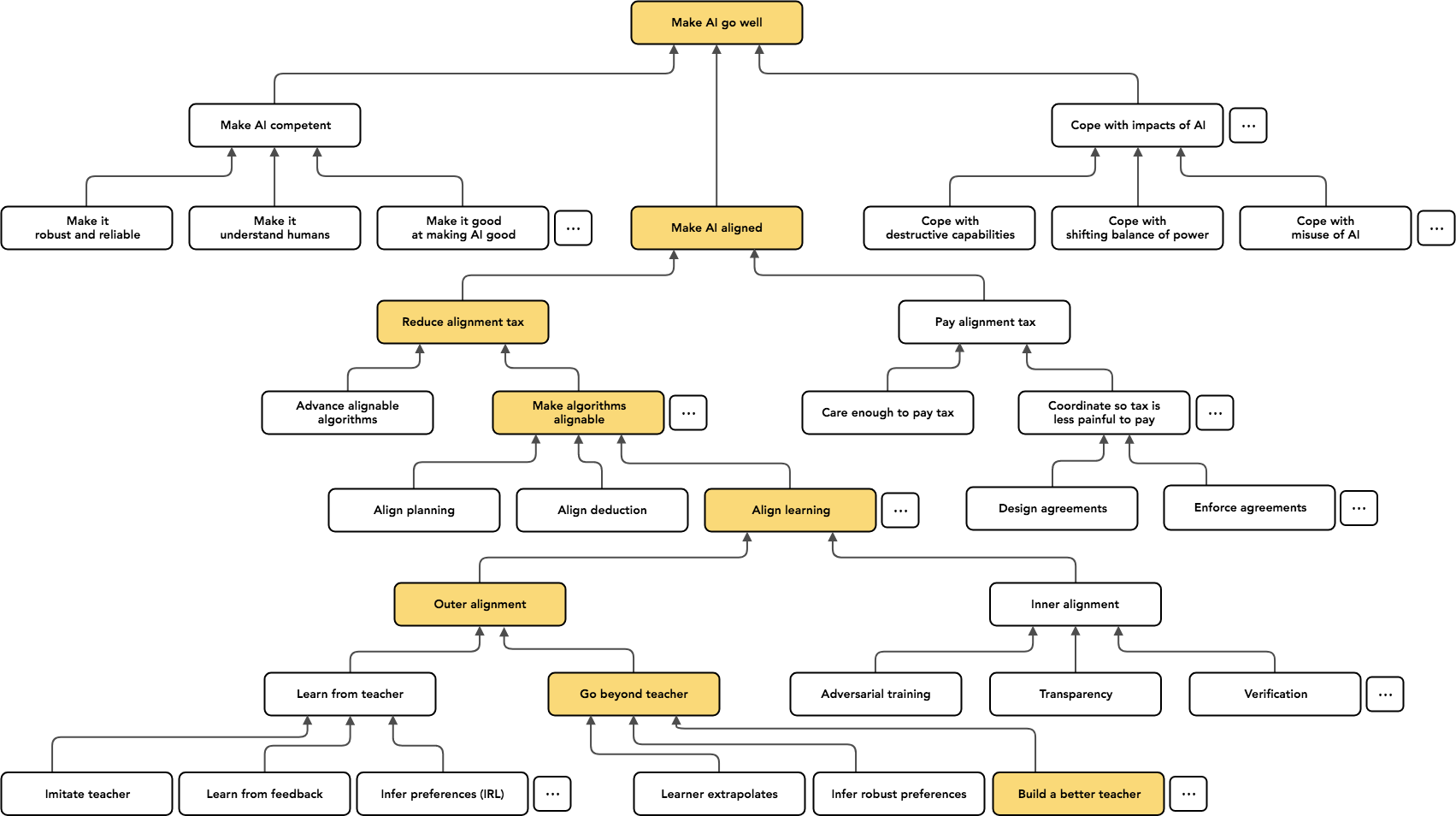 (source)
(source)
In fact, I include Paul’s tree here because it is informative to consider where I chose to make small edits to it in an attempt to include some other perspectives, as well as clarify terminological or conceptual distinctions that are needed to understand some smaller but important details of these perspectives. Clearly, though, this post would not be possible without Paul’s insightful original categorizations.
It might be helpful to have these diagrams pulled up separately while reading this post, in order to zoom as needed and to avoid having to scroll up and down while reading the discussion below.
Competence
I mostly mention the competence node here to note that depending how terms are defined, “capability robustness” (performing robustly in environments or on distributions different from those an algorithm was trained or tested in) is arguably a necessary ingredient for solving the “alignment problem” ~in full~, but more on this later. In the end, I don’t think there’s too much consequence to factoring it like Paul and I have; to “make AI go well,” our AI systems will need to be trying not to act against our interests and do so robustly in a myriad of unforeseeable situations.
(Also, remember that while competence is necessary for AI to go as well as possible, this is generally not the most differentially useful research area for contributing to this goal, since the vast majority of AI and ML research is already focused on increasing the capabilities of systems.)
Coping with impacts
Another area that is mostly outside the scope of our discussion here but still deserves mentioning is what Paul labels “cope with impacts of AI,” which would largely fall under the typical heading of AI “policy” or “governance” (although some other parts of this diagram might also typically count as “governance,” such as those under the “pay alignment tax” node). Obviously, good governance and policies will be critical, both to avoiding existential risks from AI and to achieving best possible outcomes, but much of my focus is on technical work aimed at developing what the Center for Human-Compatible Artificial Intelligence at Berkeley calls “provably beneficial systems,” as well as systems that reliably avoid bad behavior.
Deconfusion research
I added this node to the graph because I believe it represents an important area of research in the project of making AI go well. What is “deconfusion research”? As far as I’m aware, the term comes from MIRI’s 2018 Research Agenda blog post. As Nate Soares (the author of the post) puts it, “By deconfusion, I mean something like ‘making it so that you can think about a given topic without continuously accidentally spouting nonsense.’” Adam Shimi explains: “it captures the process of making a concept clear and explicit enough to have meaningful discussions about it.” This type of research corresponds to the “What even is going on with AGI?” research category Rohin discusses in his talk. Solutions to problems in this category will not directly enable us to build provably beneficial systems or reliably avoid existential risk but instead aim to resolve confusion around the underlying concepts themselves, in order for us to then be able to meaningfully address the “real” problem of making AI go well. As Nate writes on behalf of MIRI:
From our perspective, the point of working on these kinds of problems isn’t that solutions directly tell us how to build well-aligned AGI systems. Instead, the point is to resolve confusions we have around ideas like “alignment” and “AGI,” so that future AGI developers have an unobstructed view of the problem. Eliezer illustrates this idea in “The Rocket Alignment Problem,” which imagines a world where humanity tries to land on the Moon before it understands Newtonian mechanics or calculus.
Research in this category includes MIRI’s Agent Foundations Agenda (and their work on embedded agency), Eric Drexler’s work on Comprehensive AI Services (CAIS), which considers increased automation of bounded services as a potential path to AGI that doesn’t require building opaquely intelligent agents with a capacity for self-modification, Adam Shimi’s work on understanding goal directedness, MIRI/Evan Hubinger’s work on mesa-optimization and inner alignment, and David Krueger and Andrew Critch’s attempt to deconfuse topics surrounding existential risk, prepotent AI systems, and delegation scenarios in ARCHES. I won’t go into any of this work in depth here (except for more on mesa-optimization on inner alignment later), but all of it is worth looking into as you build up a picture of what’s going on in the field.
This post, the talks by Christiano and Shah by which it was inspired, and many of the clarifying posts from the Alignment Forum linked to throughout this post were also created with at least some degree of deconfusional intent. I found this post on clarifying some key hypotheses helpful in teasing apart various assumptions made in different areas and between groups of people with different perspectives. I also think Jacob Steinhardt’s AI Alignment Research Overview is worth mentioning here. It has a somewhat different flavor from and covers somewhat different topics than this/Paul’s/Rohin’s overview but still goes into a breadth of topics with some depth.
Delegation
This was another small distinction I believed was important to make in adapting Paul’s factorization of problems for this post. As proposed by Andrew Critch and David Krueger in ARCHES, and as I discussed in my blog post about ARCHES, the concept of “delegation” might be a better and strictly more general concept than “alignment.” Delegation naturally applies to the situation: humans can delegate responsibility for some task they want accomplished to one or more AI systems, and doing so successfully clearly involves the systems at least trying to accomplish these tasks in the way we intend (“intent alignment,” more on this soon). However, “alignment,” as typically framed for technical clarity, is about aligning the values or behavior of a single AI system with a single human.3 It is not particularly clear what it would mean for multiple AI systems to be “aligned” with multiple humans, but it is at least somewhat clearer what it might mean for a group of humans to successfully delegate responsibility to a group of AI systems, considering we have some sense of what it means for groups of humans to successfully delegate to other groups of humans (e.g. through organizations). Within this framework, “alignment” can be seen as a special case of delegation, what Critch and Krueger call “single/single” delegation (delegation from one human to one AI system). See below (“Single/single delegation (alignment)”) for more nuance on this point, however. I believe this concept largely correlates with Shah’s “Helpful AGI” categorization in his overview talk; successful delegation certainly depends in part on the systems we delegate to being helpful (or, at minimum, trying to be).
Delegation involving multiple stakeholders and/or AIs
One of the reasons ARCHES makes the deliberate point of distinguishing alignment as a special case of delegation is to show that solving alignment/successfully delegating from one user to one system is insufficient for addressing AI-related existential risks (and, by extension, for making AI go well). Risk-inducing externalities arising from out of the interaction of individually-aligned systems can still pose a threat and must be addressed by figuring out how to successfully delegate in situations involving multiple stakeholders and/or multiple AI systems. This is the main reason I chose to make Paul’s “alignment” subtree a special case of delegation more generally. I won’t go into too much more detail about these “multi-” situations here, partially because there’s not a substantial amount of existing work to be discussed. However, it is worth looking at ARCHES, as well as this blog post by Andrew Critch and my own blog post summarizing ARCHES, for further discussion and pointers to related material.
I would be interested to know to what extent Christiano thinks this distinction is or is not helpful in understanding the issues and contributing to the goal of making AI go well. It is clear by his own diagram that “making AI aligned” is not sufficient for this goal, and he says as much in this comment in response to the aforementioned blog post by Critch: “I totally agree that there are many important problems in the world even if we can align AI.” But the rest of that comment also seems to somewhat question the necessity of separately addressing the multi/multi case before having a solution for the single/single case, if there might be some “‘default’ ways” of approaching the multi/multi case once armed with a solution to the single/single case. To me, this seems like a disagreement on the differential importance between research areas rather than a fundamental difference about the underlying concepts in principle, but I would be interested in more discussion on this point from the relevant parties. And it is nonetheless possible that solving single/single delegation or being able to align individual systems and users could be a necessary prerequisite to solving the multi- cases, even if we can begin to probe the more general questions without a solution for the single/single case.
(ETA 12/30/20: Rohin graciously gave me some feedback on this post and had the following to say on this point)
I’m not Paul, but I think we have similar views on this topic – the basic thrust is:
- Yes, single-single alignment does not guarantee that AI goes well; there are all sorts of other issues that can arise (which ARCHES highlights).
- We’re focusing on single-single alignment because it’s a particularly crisp technical problem that seems amenable to technical work in advance – you don’t have to reason about what governments will or won’t do, or worry about how people’s attitudes towards AI will change in the future. You are training an AI system in some environment, and you want to make sure the resulting AI system isn’t trying to hurt you. This is a more “timeless” problem that doesn’t depend as much on specific facts about e.g. the current political climate.
- A single-single solution seems very helpful for multi-multi alignment; if you care about e.g. fairness for the multi-multi case, it would really help if you had a method of building an AI system that aims for the human conception of fairness (which is what the type of single-single alignment that I work on can hopefully do).
- The aspects of multi-multi work that aren’t accounted for by single-single work seem better handled by existing institutions like governments, courts, police, antitrust, etc rather than technical research. Given that I have a huge comparative advantage at technical work, that’s what I should be doing. It is still obviously important to work on the multi-multi stuff, and I am very supportive of people doing this (typically under the banner of AI governance, as you note).
(In Paul’s diagram, the multi-multi stuff goes under the “cope with the impacts of AI” bucket.)
I suspect Critch would disagree most with point 4 and I’m not totally sure why.
Single/single delegation (alignment)
It’s important to make clear what we mean by “alignment” and “single/single delegation” in our discussions, since there are a number of related but distinct formulations of this concept that are important to disambiguate in order to bridge inferential gaps, combat the illusion of transparency, and deconfuse the concept. Perhaps the best starting point for this discussion is David Krueger’s post on disambiguating “alignment”, where he distinguishes between several variations of the concept:
- Holistic alignment: “Agent R is holistically aligned with agent H iff R and H have the same terminal values. This is the ‘traditional AI safety (TAIS)’ (as exemplified by Superintelligence) notion of alignment, and the TAIS view is roughly: ‘a superintelligent AI (ASI) that is not holistically aligned is an Xrisk’; this view is supported by the instrumental convergence thesis.”
- Parochial alignment: “I’m lacking a satisfyingly crisp definition of parochial alignment, but intuitively, it refers to how you’d want a ‘genie’ to behave: R is parochially aligned with agent H and task T iff R’s terminal values are to accomplish T in accordance to H’s preferences over the intended task domain… parochially aligned ASI is not safe by default (it might paperclip), but it might be possible to make one safe using various capability control mechanisms”
- Sufficient alignment: “R is sufficiently aligned with H iff optimizing R’s terminal values would not induce a nontrivial Xrisk (according to H’s definition of Xrisk). For example, an AI whose terminal values are ‘maintain meaningful human control over the future’ is plausibly sufficiently aligned. It’s worth considering what might constitute sufficient alignment short of holistic alignment. For instance, Paul seems to argue that corrigible agents are sufficiently aligned.”
- Intent alignment (Paul Christiano’s version of alignment): “R is intentionally aligned with H if R is trying to do what H wants it to do.”
- “Paul also talks about benign AI which is about what an AI is optimized for (which is closely related to what it ‘values’). Inspired by this, I’ll define a complementary notion to Paul’s notion of alignment: R is benigned with H if R is not actively trying to do something that H doesn’t want it to do.”
Each of these deserves attention, but let’s zoom in on intent alignment, as it is the version of alignment that Paul uses in his map and that he seeks to address with his research. First, I want to point out that each of Krueger’s definitions pertains only to agents. However, I think we still want a definition of alignment that can apply to non-agential AI systems, since it is an open question whether the first AGI will be agentive. Comprehensive AI Services (CAIS) explicitly pushes back against this notion, and ARCHES frames its discussion around AI “systems” to be “intentionally general and agent-agnostic.” (See also this post on clarifying some key hypotheses for more on this point.) It is clear that we want to have some notion alignment that applies just as well to AI systems that are not agents or agent-like. In fact, Paul’s original definition does not seem to explicitly rely on agency:
When I say an AI A is aligned with an operator H, I mean:
A is trying to do what H wants it to do.
Another characterization of intent alignment comes from Evan Hubinger: “An agent is intent aligned if its behavioral objective4 is aligned with humans” (presumably he means “aligned” in this same sense that its behavioral objective is incentivizing trying to do what we want). I like that this definition uses the more technically clear notion of a behavioral objective because it allows the concept to more precisely be placed in a framework with outer and inner alignment (more on this later), but I still wish it did not depend on a notion of agency like Krueger’s definition. Additionally, all of these definitions lack the formal rigor that we need if we want to be able to “use mathematics to formally verify if a proposed alignment mechanism would achieve alignment,” as noted by this sequence on the Alignment Forum. David Krueger makes a similar point in his post, writing, “Although it feels intuitive, I’m not satisfied with the crispness of this definition [of intent alignment], since we don’t have a good way of determining a black box system’s intentions. We can apply the intentional stance, but that doesn’t provide a clear way of dealing with irrationality.” And Paul himself makes very similar points in his original post:
- “This definition of ‘alignment’ is extremely imprecise. I expect it to correspond to some more precise concept that cleaves reality at the joints. But that might not become clear, one way or the other, until we’ve made significant progress.”
- “One reason the definition is imprecise is that it’s unclear how to apply the concepts of ‘intention,’ ‘incentive,’ or ‘motive’ to an AI system. One naive approach would be to equate the incentives of an ML system with the objective it was optimized for, but this seems to be a mistake. For example, humans are optimized for reproductive fitness, but it is wrong to say that a human is incentivized to maximize reproductive fitness.”5
All of these considerations indicate that intent alignment is itself a concept in need of deconfusion, perhaps to avoid a reliance on agency, to make the notion of “intent” for AI systems more rigorous, and/or for other reasons entirely.
Leaving this need aside for the moment, there are a few characteristics of the “intent alignment” formulation of alignment that are worth mentioning. The most important point to emphasize is that an intent-aligned system is trying to do what its operator wants it to, and not necessarily actually doing what its operator wants it to do. This allows competence/capabilities to be factored out as a separate problem from (intent) alignment; an intent-aligned system might make mistakes (for example, by misunderstanding an instruction or by misunderstanding what its operator wants6), but as long as it is trying to do what its operator wants, the hope is that catastrophic outcomes can be avoided with a relatively limited amount of understanding/competence. However, if we instead define “alignment” only as a function of what the AI actually does, an aligned system would need to be both trying to do the right thing and actually accomplishing this objective with competence. As Paul says in his overview presentation, “in some sense, [intent alignment] might be the minimal thing you want out of your AI: at least it is trying.” This highlights why intent alignment might be an instrumentally more useful concept for working on making AI go well: while the (much) stronger condition of holistic alignment would almost definitionally guarantee that a holistically aligned system will not induce existential risks by its own behavior, it seems much harder to verify that a system and a human share the same terminal values than to verify that a system is trying to do what the human wants.
It’s worth mentioning here the concept of corrigibility. The page on Arbital provides a good definition:
A ‘corrigible’ agent is one that doesn’t interfere with what we would intuitively see as attempts to ‘correct’ the agent, or ‘correct’ our mistakes in building it; and permits these ‘corrections’ despite the apparent instrumentally convergent reasoning saying otherwise.
This intuitively feels like a property we might like the AI systems we build to have as they get more powerful. In his post, Paul argues:
- A benign act-based agent will be robustly corrigibile if we want it to be.
- A sufficiently corrigible agent will tend to become more corrigible and benign over time. Corrigibility marks out a broad basin of attraction towards acceptable outcomes.
As a consequence, we shouldn’t think about alignment as a narrow target which we need to implement exactly and preserve precisely. We’re aiming for a broad basin, and trying to avoid problems that could kick [us] out of that basin.
While Paul links corrigibility to benignment explicitly here, how it relates to intent alignment is somewhat less clear to me. I think it’s clear that intent alignment (plus a certain amount of capability) entails corrigibility: if a system is trying to “do what we want,” and is at least capable enough to figure out that we want it to be corrigible, then it will do its best to be corrigible. I don’t think the opposite direction holds, however: I can imagine a system that doesn’t interfere with attempts to correct it and yet isn’t trying to “do what we want.” The point remains, though, that if we’re aiming for intent alignment, it seems that corrigibility will be a necessary (if not sufficient) property.
Returning to the other definitions of alignment put forth by Krueger, one might wonder if there is any overlap between these different notions of alignment. Trivially, a holistically aligned AI would be parochially aligned for any task T, as well as sufficiently aligned. David also mentions that “Paul seems to argue that corrigible agents are sufficiently aligned,” which does seem to be a fair interpretation of the above “broad basin” argument. The one point I’ll raise, though, is that Paul specifically argues that “benign act-based agents will be robustly corrigible” and “a sufficiently corrigible agent will tend to become more corrigible and benign over time,” which seems to imply corrigibility can give you benignment. By David’s definition of benignment (“not actively trying to do something that H doesn’t want it to do”), this would represent sufficient alignment, but Paul defined benign AI in terms of what it was optimized for. If such an optimization process were to produce a misaligned mesa-optimizer, it would clearly not be sufficiently aligned. Perhaps the more important point, however, is that it seems Paul would argue that intent alignment would in all likelihood represent sufficient alignment (others may disagree).
I would also like to consider if and how the concept of single/single delegation corresponds to any of these specific types of alignment. As put forth in ARCHES:
Single(-human)/single(-AI system) delegation means delegation from a single human stakeholder to a single AI system (to pursue one or more objectives).
Firstly, it is probably important to note that “single/single delegation” refers to a task, and “alignment,” however it is defined, is a property that we want our AI systems to have. However, to solve single/single delegation (or to do single/single delegation successfully), we will require a solution to the “alignment problem,” broadly speaking. From here, it’s a question of defining what would count as a “solution” to single/single delegation (or what it would mean to do it “successfully”). If we can build intent aligned systems, will we have solved single/single delegation? If they are sufficiently capable, probably. The same goes for parochially aligned and holistically aligned systems: if they’re sufficiently capable, the users they’re aligned with can probably successfully delegate to them. It is unclear to me whether this holds for a sufficiently aligned system, however; knowing that “optimizing R’s terminal values would not induce a nontrivial Xrisk” doesn’t necessarily mean that R will be any good at doing the things H wants it to.
As I mentioned before, I like the concept of “delegation” because it generalizes better to situations involving multiple stakeholders and/or AI systems. However, I believe it is still necessary to understand these various notions of “alignment,” because it remains a necessary property for successfully delegating in the single/single case and because understanding the differences between them is helpful for understanding others’ work and in communicating about the subject.
Alignment tax and alignable algorithms
One compelling concept Paul used that I had not heard before was the “alignment tax”: the cost incurred from insisting on (intent) alignment. This is intended to capture the tension between safety and competence. We can either pay the tax, e.g. by getting policymakers to care enough about the problem, negotiating agreements to coordinate to pay the tax, etc., or we can reduce the tax with technical safety and alignment research that produces aligned methods that are roughly competitive with unaligned methods.
Two ways that research can reduce the alignment tax are 1) advancing alignable algorithms (perhaps algorithms that have beliefs and make decisions that are easily interpretable by humans) by making them competitive with unaligned methods and 2) making existing algorithms alignable:
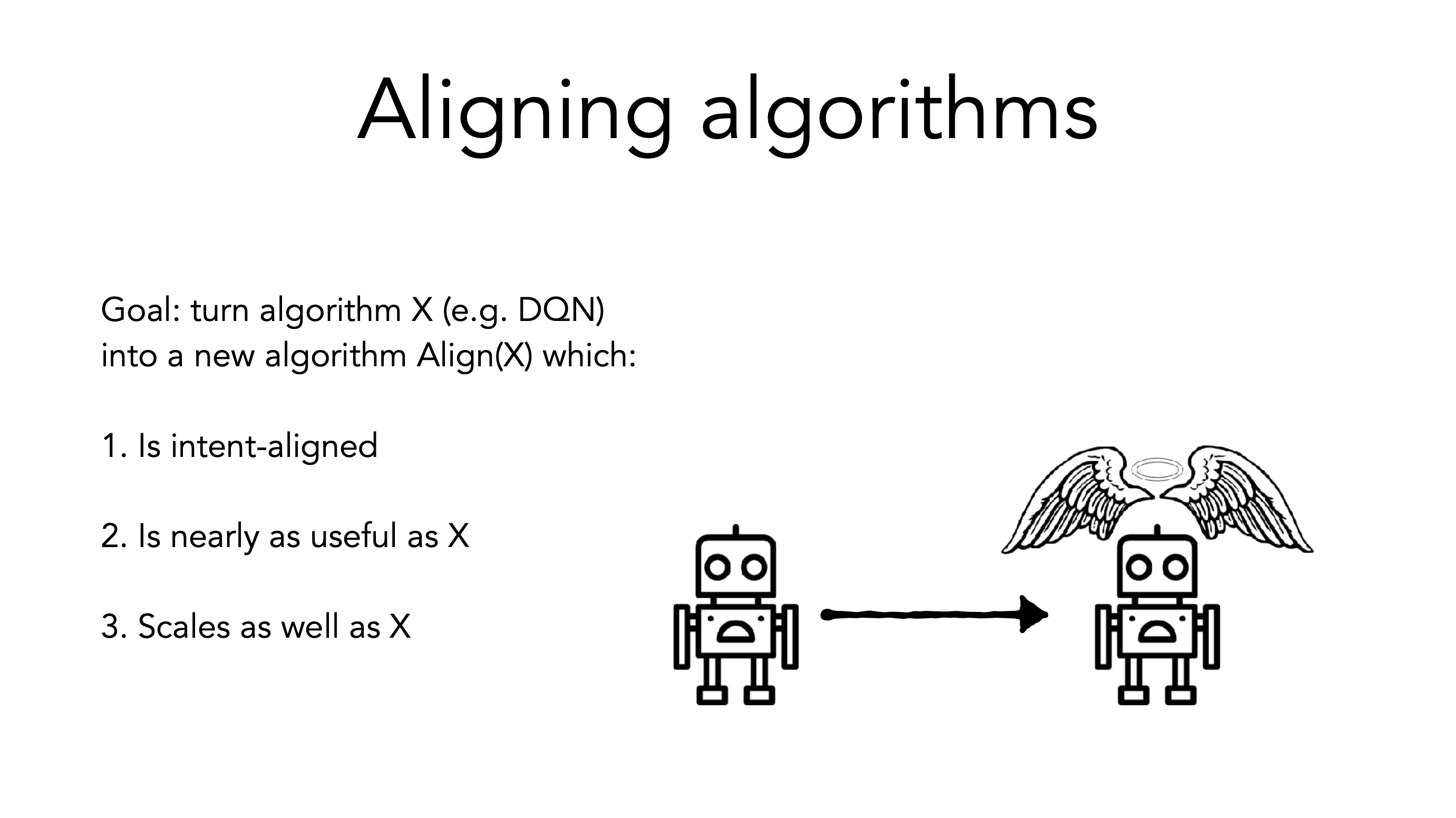 (source)
(source)
Paul then considers different types of algorithms (or, potentially, different algorithmic building blocks in an intelligent system) we might try and align, like algorithms for planning, deduction, and learning. With planning, we might have an alignment failure if the standard by which an AI evaluates actions doesn’t correspond to what we want, or if the algorithm is implicitly using a decision theory that we don’t think is correct. The former sounds much like traditional problems in (mis)specifying reward or objective functions for learners. I think problems in decision theory are very interesting, but unfortunately I have not yet been able to learn as much about the subject as I’d like to. The main thrust of this research is to try and solve perceived problems with traditional decision theories (e.g. causal decision theory and evidential decision theory) in scenarios like Newcomb’s problem. Two decision theory variants I’ve seen mentioned in this context are functional decision theory and updateless decision theory. (This type of research could also be considered deconfusion work.)
As for aligning deduction algorithms, Paul only asks “is there some version of deduction that avoids alignment failures?” and mentions “maybe the alignment failures in deduction are a little more subtle” but doesn’t go into any more detail. After searching for posts on the Alignment Forum and LessWrong about how deduction could be malign failed to surface anything, I can’t help but wonder if he really might be referring to induction. For one, I’m having trouble imagining what it would mean for a deductive process to be malign. From my understanding, the axioms and rules of inference that define a formal logical system completely determine the set of theorems that can be validly derived from them, so if we were unhappy with the outputs of a deductive process that is validly applying its rules of inference, wouldn’t that mean that we really just have a problem with our own choice of axioms and/or inference rules? I can’t see where a notion of “alignment” would fit in here (but somebody please correct me if I’m wrong here… I would love to hear Paul’s thoughts about these potentially “subtle” misalignment issues in deduction).
The other reason I’m suspicious Paul might’ve actually meant induction is because Paul himself wrote the original post arguing that the universal prior in Solomonoff induction is malign. I won’t discuss this concept too much here because it still confuses me somewhat (see here, here, and here for more discussion), but it certainly seems to fit the description of being a “subtle” failure mode. I’ll also mention MIRI’s paper on logical induction (for dealing with reasoning under logical uncertainty) here, as it seems somewhat relevant to the idea of alignment as it corresponds to deduction and/or induction.
(ETA 12/30/20: Rohin also had the following to say about deduction and alignment)
I’m fairly confident he does mean deduction. And yes, if we had a perfect and valid deductive process, then a problem with that would imply a problem with our choice of axioms and inference rules. But that’s still a problem!
Like, with RL-based AGIs, if we had a perfect reward-maximizing policy, then a problem with that would imply a problem with our choice of reward function. Which is exactly the standard argument for AI risk.
There’s a general argument for AI risk, which is that we don’t know how to give an AI instructions that it actually understands and acts in accordance to – we can’t “translate” from our language to the AI’s language. If the AI takes high impact actions, but we haven’t translated properly, then those large impacts may not be the ones we want, and could be existentially bad. This argument applies whether our AI gets its intelligence from induction or deduction.
Now an AI system that just takes mathematical axioms and finds theorems is probably not dangerous, but that’s because such an AI system doesn’t take high impact actions, not because the AI system is aligned with us.
Outer alignment and objective robustness/inner alignment
For learning algorithms, Paul breaks the alignment problem into two parts: outer alignment and inner alignment. This was another place where I felt it was important to make a small change to Paul’s diagram, as a result of some recent clarification on terminology relating to inner alignment by Evan Hubinger. It’s probably best to first sketch the concepts of objective robustness, mesa-optimization, and inner alignment for those who may not already be familiar with the concept.
First, recall that the base objective for a learning algorithm is the objective we use to search through models in an optimization process and that the behavioral objective is what the model (produced by this process) itself appears to be optimizing for: the objective that would be recovered from perfect inverse reinforcement learning. If the behavioral objective is aligned with the base objective, we say that the model is objective robust; if there is a gap between the behavioral objective and the base objective, the model will continue to appear to pursue the behavioral objective, which could result in bad behavior off-distribution (even as measured by the base objective). As a concrete (if simplistic) example, imagine that a maze-running reinforcement learning agent is trained to reach the end of the maze with a base objective that optimizes for a reward which it receives upon completing a maze. Now, imagine that in every maze the agent was trained on, there was a red arrow marking the end of the maze, and that in every maze in the test set, this red arrow is at a random place within the maze (but not the end). Do we expect our agent will navigate to the end of the maze, or will it instead navigate to the red arrow? If the training process produces an agent that learned the behavioral objective “navigate to the red arrow,” because red arrows were a very reliable proxy for/predictor of reward during the training process, it will navigate to the red arrow, even though this behavior is now rated poorly by the reward function and the base objective.
One general way we can imagine failing to achieve objective robustness is if our optimization process itself produces an optimizer (a mesa-optimizer)—in other words, when that which is optimized (the model) becomes an optimizer. In the above example, we might imagine that such a model, trained with something like SGD, could actually learn something like depth- or breadth-first search to optimize its search for paths to the red arrow (or the end of the maze). We say that the mesa-objective is the objective the mesa-optimizer is optimizing for. (In the case of a mesa-optimizer, its mesa-objective is definitionally its behavioral objective, but the concept of a behavioral objective remains applicable even when a learned model is not a mesa-optimizer.) We also say that a mesa-optimizer is inner aligned if its mesa-objective is aligned with the base objective. Outer alignment, correspondingly, is the problem of eliminating the gap between the base objective (what we optimize our models for) and the intended goal (what we actually want from our model).
I write all this to emphasize one of the main points of Evan Hubinger’s aforementioned clarification of terminology: that we need outer alignment and objective robustness to achieve intent alignment, and that inner alignment is a way of achieving objective robustness only in the cases where we’re dealing with a mesa-optimizer. Note that Paul defines inner alignment in his talk as the problem of “mak[ing] sure that policy is robustly pursuing that objective”; I hope that this section makes clear that this is actually the problem of objective robustness. Even in the absence of mesa-optimization, we still have to ensure objective robustness to get intent alignment. This is why I chose to modify this part of Paul’s graph to match this nice tree from Evan’s post:
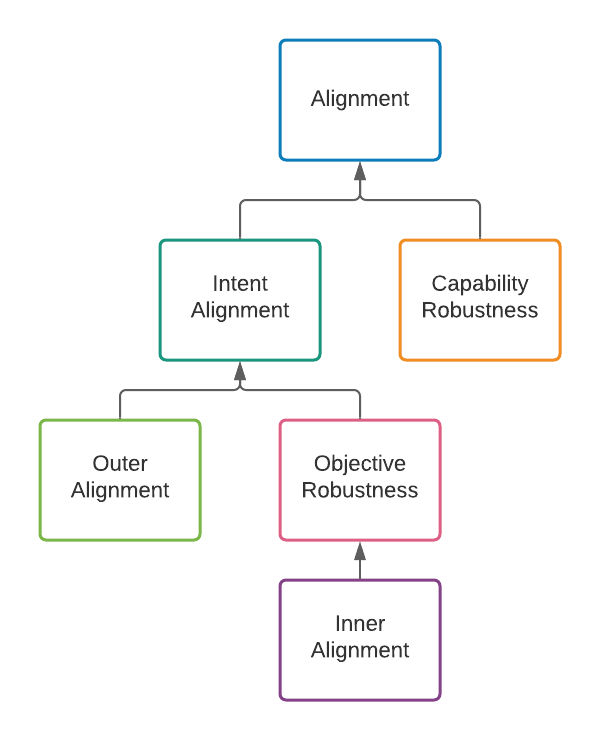 (
(Paul mentions adversarial training, transparency, and verification as potential techniques that could help ensure objective robustness/inner alignment. These have more typically been studied in the context of robustness generally, but the hope here is that they can also be applied usefully in the context of objective robustness. Objective robustness and inner alignment are still pretty new areas of study, however, and how we might go about guaranteeing them is a very open question, especially considering nobody has yet been able to concretely produce/demonstrate a mesa-optimizer in the modern machine learning context. It might be argued that humanity can be taken as an existence proof of mesa-optimization, since, if we are optimizing for anything, it is certainly not what evolution optimized us for (reproductive fitness). But, of course, we’d like to be able to study the phenomenon in the context it was originally proposed (learning algorithms). For more details on inner alignment and mesa-optimization, see Risks from Learned Optimization, Evan’s clarifying blog post, and this ELI12 post on the topic.
Approaches to outer alignment
Paul subdivides work into outer alignment into two categories: cases where we want an AI system to learn (aligned) behavior from a teacher and cases where we want an AI system to go beyond the abilities of any teacher (but remain aligned). According to Paul, these cases roughly correspond to the easy and hard parts of outer alignment, respectively. In the short term, there are obviously many examples of tasks that humans already perform that we would like AIs to be able to perform more cheaply/quickly/efficiently (and, as such, would benefit from advances in “learn from teacher” techniques), but in the long term, we want AIs to be able to exceed human performance and continue to do well (and remain aligned) in situations that no human teacher understands.
Learning from teacher
If we have a teacher that understands the intended behavior and can demonstrate and/or evaluate it, we can 1) imitate behavior demonstrated by the teacher, 2) learn behavior the teacher thinks is good, given feedback, or 3) infer the values/preferences that the teacher seems to be satisfying (e.g. with inverse reinforcement learning)9, and then optimize for these inferred values. Paul notes that a relative advantage of the latter two approaches is that they tend to be more sample-efficient, which becomes more relevant as acquiring data from the teacher becomes more expensive. I should also mention here that, as far as I’m aware, most “imitation learning” is really “apprenticeship learning via inverse reinforcement learning,” where the goal of the teacher is inferred in order to be used as a reward signal for learning the desired behavior. So, I’m not exactly sure to what degree categories 1) and 3) are truly distinct, since it seems rare to do “true” imitation learning, where the behavior of the teacher is simply copied as closely as possible (even behaviors that might not contribute to accomplishing the intended task).
For further reading on techniques that learn desired behavior from a teacher, see OpenAI’s “Learning from Human Preferences” and DeepMind’s “Scalable agent alignment via reward modeling” on the “learn from feedback” side of things. On the infer preferences/IRL side, start with Rohin Shah’s sequence on value learning on the Alignment Forum and Dylan Hadfield-Mennell’s papers “Cooperative Inverse Reinforcement Learning” and “Inverse Reward Design.”
Going beyond teacher
If we want our AI systems to exceed the performance of the teacher, making decisions that no human could or understanding things that no human can, alignment becomes more difficult. In the previous setting, the hope is that the AI system can learn aligned behavior from a teacher who understands the desired (aligned) behavior well enough to demonstrate or evaluate it, but here we lack this advantage. Three potential broad approaches Paul lists under this heading are 1) an algorithm that has learned from a teacher successfully extrapolates from this experience to perform at least as well as the teacher in new environments, 2) infer robust preferences, i.e. infer the teacher’s actual preferences or values (not just stated or acted-upon preferences), in order to optimize them (this approach also goes by the name of ambitious value learning), and 3) build a better teacher, so you can fall back to approaches from the “learn from teacher” setting, just with a more capable teacher.
Of the three, the first seems the least hopeful; machine learning algorithms have historically been pretty notoriously bad at extrapolating to situations that are meaningfully different than those they encountered in the training environment. Certainly, the ML community will continue to search for methods that generalize increasingly well, and, in turn, progress here could make it easier for algorithms to learn aligned behavior and extrapolate to remain aligned in novel situations. However, this does not seem like a reasonable hope at this point for keeping algorithms aligned as they exceed human performance.
The allure of the second approach is obvious: if we could infer, essentially, the “true human utility function,” we could then use it to train a reinforcement agent without fear of outer alignment failure/being Goodharted as a result of misspecification error. This approach is not without substantial difficulties, however. For one, in order to exceed human performance, we need to have a model of the mistakes that we make, and this error model cannot be inferred alongside the utility function without additional assumptions. We might try and specify a specific error model ourselves, but this seems as prone to misspecification as the original utility function itself. For more information on inferring robust preferences/ambitious value learning, see the “Ambitious Value Learning” section of the value learning sequence. Stuart Armstrong also seems to have a particular focus in this area, e.g. here and here.
The two most common “build a better teacher” approaches are amplification and debate. Amplification is what Paul spends most of his time on and the approach of which he’s been the biggest proponent. The crux of the idea is that a good starting point for a smarter-than-human teacher is a group of humans. We assume that even if a human cannot answer a question, they can decompose the question into sub-questions such that knowing the answers to the sub-questions would enable them to construct the answer to the answer to the original question. The hope, then is to build increasingly capable AI systems by training a question-answering AI to imitate the output of a group of humans answering questions in this decompositional fashion, then recursively building stronger AIs using a group of AIs from the last iteration answering decomposed questions as an overseer:
 (source)
(source)
The exponential tree that this recursive process tries to approximate in the limit is called HCH (for Humans Consulting HCH). There is much more detail and many more important considerations in this scheme than I can address here, e.g. the distillation step, how this scheme hopes to maintain intent alignment throughout the recursive process, and (importantly) if this exponential tree can answer any question in the limit.10 There are also two distinct types of amplification: imitative amplification, where the AI systems are trained to imitate the outputs of the last tree in the amplification step, and approval-based amplification, where the AI systems are trained to produce outputs or perform actions of which this tree would approve. For more on amplification, see the iterated amplification sequence on the Alignment Forum, the original paper and Paul Christiano’s writings and papers, more generally. See also recursive reward modeling, another “build a better teacher” approach which “can be thought of as an instance of iterated amplification.” For basic research into this method of solving complex problems by recursively solving subproblems, see Ought’s work on factored cognition.
Debate (more recent progress update here) builds a better teacher by training agents to debate a topic against each other in an adversarial game and have a human decide the winner based on the sequence of arguments made by the agents, so the agents incrementally build each other into both better teachers and more competent students (in practice, it would likely be just one agent trained via self-play). For this to work, it needs to be true that 1) judging debates is easier than debating (so humans can judge the quality of arguments that they could not have come up with themselves) and 2) lying is harder than arguing against a lie, given this human judge (so the adversarial game will reliably reward truth-telling).
There is a close relationship between amplification and debate. Section 7 in the original debate paper explores this relationship in detail and is worth reading, but the basic connection can be highlighted by seeing the amplification setup in terms of three modules: an answerer, a questioner, and a checker. The answerer is the ML system being iteratively trained to answer questions by imitating the output of the overseer answering questions recursively, the questioner decomposes the question into the relevant sub-questions, and the checker takes the sub-questions and their answers and generates an answer to the original question. (Christiano’s setup treats the questioner and the checker as the same module—in the base case, a human.) Debate differs from this setup by training the answerer and the questioner against each other adversarially while keeping the human judge/checker. This gives debate a potential advantage if generating sub-questions is superhumanly difficult (e.g. if the branching factor of HCH is too high). Again, section 7 of the original paper covers more of the differences and similarities between these two approaches and should be read in full. Relatedly, Evan Hubinger has written a post on synthesizing amplification and debate that might be of interest.
One final resource I want to mention while discussing techniques for going beyond a teacher is Evan Hubinger’s overview of 11 proposals for safe advanced AI, which includes many of the basic techniques already mentioned here but goes into more depth discussing the relative advantages and disadvantages of each approach in the contexts of outer and inner alignment. In practice, an outer alignment approach (e.g. imitative or approval-based amplification) is often paired with some technique aimed at preventing inner alignment failures (e.g. adversarial training, transparency, etc.).
Conclusion
That’s about it! We’ve covered a lot of ground here. This post ended up being much longer than I anticipated, but I wanted to give a cursory overview of as many of these ideas as possible and elaborate a little on how they interrelate before providing pointers to further material for the interested reader.
I hope this post has been helpful in giving you a lay of the land in ongoing work in AI existential safety and alignment and (more importantly) in helping you build or refine your own mental map of the field (or simply check it, if you’re one of the many people who has a better map than mine!). Building this mental map has already been helpful to me as I assimilate new information and research and digest discussions between others in the field. It’s also been helpful as I start thinking about the kinds of questions I’d like to address with my own research.
Rohin also did a two part podcast with the Future of Life Institute discussing the contents of his presentation in more depth, both of which are worth listening to. ↩
See this post for specific commentary on this sequence from others in the field. ↩
Sometimes, people use “alignment” to refer to the overall project of making AI go well, but I think this is misguided for reasons I hope are made clear by this post. From what I’ve seen, I believe my position is shared by most in the community, but please feel free to disagree with me on this so I can adjust my beliefs if needed. ↩
“Behavioral objective: The behavioral objective is what an optimizer appears to be optimizing for. Formally, the behavioral objective is the objective recovered from perfect inverse reinforcement learning.” ↩
Here, Paul seems to have touched upon the concept of mesa-optimization before it was so defined. More on this topic to follow. ↩
That an intent-aligned AI can be mistaken about what we want is a consequence of the definition being intended de dicto rather than de re; as Paul writes, “an aligned A is trying to ‘do what H wants it to do’” (not trying to do “that which H actually wants it to do”). ↩
Arrows are implications: “for any problem, if its direct subproblems are solved, then it should be solved as well (though not necessarily vice versa).” ↩
Note that Evan also has capability robustness as a necessary component, along with intent alignment, for achieving “alignment.” This fits well with my tree, where we need both alignment (which, in the context of both my and Paul’s trees, is intent alignment) and capability robustness to make AI go well; the reasoning is much the same even if the factorization is slightly different. ↩
Paul comments that this type of approach involves some assumption that relates the teacher’s behavior to their preferences (e.g. an approximate optimality assumption: the teacher acts to satisfy their preferences in an approximately optimal fashion). ↩
I want to mention here that Eliezer Yudkowsky wrote a post challenging Paul’s amplification proposal (which includes responses from Paul), in case the reader is interested in exploring pushback against this scheme. ↩